Originally, I had intended to write an article about a new Home Lab project I am working on using Docker for application virtualization, ESXi for operating system virtualization, and hardware reconfigurations for TrueNAS by swapping components from multiple servers. However, it turned out to be incredibly more involved than a single article would be able to encompass. As I continue to work on that (I am at 46 pages of notes so far), I figured I would write about a subject that some people are not aware of — deduplication or rather deduplication when combined with ZFS.
For the purposes of this article, I will assume that you know what ZFS and FreeNAS/TrueNAS are. If not, please have a look at Craft Computing for a good video on what it is and how to set it up on a spare computer.
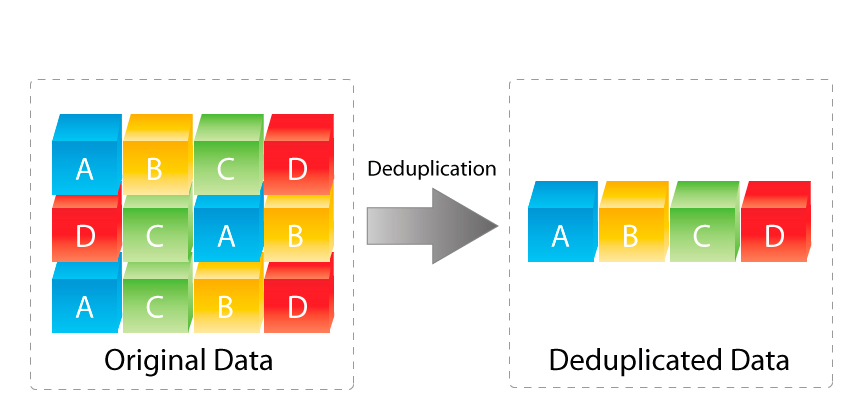
So what is deduplication?
Essentially, it is a way for your filesystem to keep track of duplicate items on your drive as well as possible changes and incremental differences between those items. For example, if you are like me and try to backup your family photos from several different iPhones to a shared drive then you know that sometimes you just copy all folders into it and you might end up with duplicates of those same files. That is where deduplication comes in. It says, “hey, I see this exact file in several folders. I will just keep a single file of it and then the other places that have the file will just be a reference point and not take any space at all.” That means you can save a lot of space, especially if you have something like Skyrim in your Steam Library complete with modifications and then a copy of it in case you screw it up somehow.
So how is this different from compression?
Compression is about applying an algorithm to be more efficient with space savings and it will never be a 100% savings. It is another tool in your belt to gain additional space efficiencies and is similar to what IBM Stacker did back in the 90s. Note, I actually remember seeing those boxes on sale in the software section of Target. /Nostalgia
So what kind of savings are we talking about with dedupe?
It depends. If it is an exact copy of a file then that is a 100% savings since there are no bits being copied. If the file has changed slightly then it would be the difference between the original and the new file.
So what does that look like from a volume standpoint?
For this test, I used two datasets from the same TrueNAS device. In the image I mounted the main R430-6TB-Z2 root For this test, I used a dataset from the same TrueNAS device. In the image I mounted the main R430-6TB-Z2 root share as well as the underlying Vault share. I copied files from one file share directory, named Software, into a different one, named Vault.
The top folder called Projects is running LZ4 compression and no deduplication which is pretty standard for default TrueNAS datasets. The bottom folder is running LZ4 compression with deduplication. If you look carefully, you can see they both have the same number of files and folders, but the bottom folder is indeed smaller.
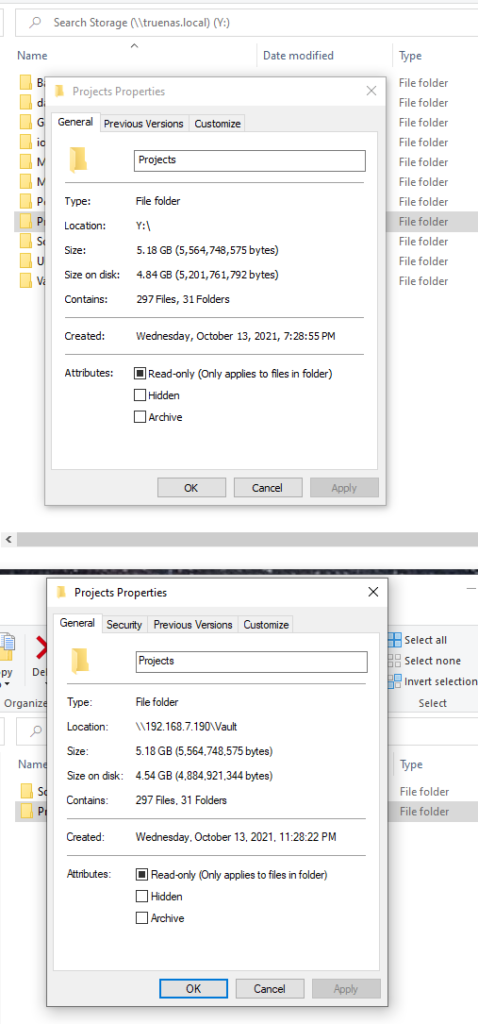
If you were to make multiple copies of the files, then ZFS would simply link to those files like a hyperlink or shortcut. The file explorer for the operating system would report it as taking up twice as much space due to the copy, but TrueNAS would report it as higher compression. Notice that the compression ratio is higher than 1.00 at 1.05 on Vault which indicates space savings.
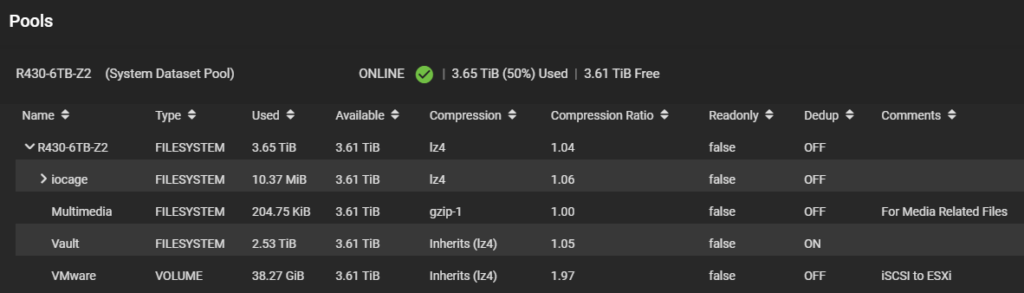
However, if you open the TrueNAS shell and look at the zpool list you can see the real deduplication value. In this case, 2.08x or more than twice the value of 1.0 which indicates multiple copies of files.

If you are wondering about the VMware Volume and why it has a high level of compression, here is what is what my ESXi host looks like. Note, all VMDKs are using thin provisioning.

In the next article I will try to piece together some of the things I have done. Docker, Alfred, and Jarvis are all running Docker containers. From a dedupe standpoint, those VMs are very similar running Ubuntu with Docker with the only difference being the containers themselves. This means great space savings and more efficiencies.
So what kind of resources does it really take?
A lot of people complain that deduplication needs an incredible amount of system resources. However, truth is a three edged sword. It is true that it does need additional memory as the memory is where the references and links to all of the files are being held together, but the rule of thumb I have read is about 1 (to 3) GB of additional memory for each TB of data using deduplication.
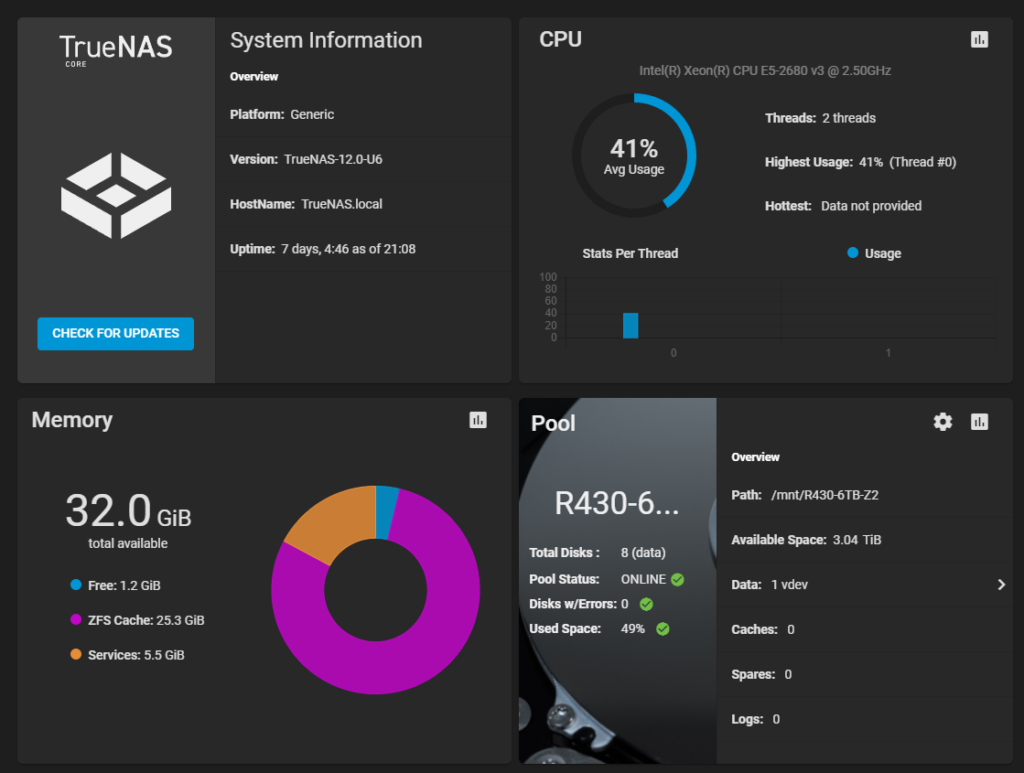
If you are wondering about the ZFS Cache and why there is so little free memory, that is because ZFS will always use all available memory to cache just like how SQL will. In my case, I had additional memory in my server so I assigned more memory to it, but I did not notice a difference in performance other than bursts for file copies. The beauty of virtualization is that you can scale up or down as needed. Since my VM guests are light, I might increase the cache for now.
From a processor and utilization aspect, it is not extremely heavy. I limited my virtual machine to 2 processors and vSphere monitoring showed that TrueNAS only used about 60% of the processors during the copy/write process.
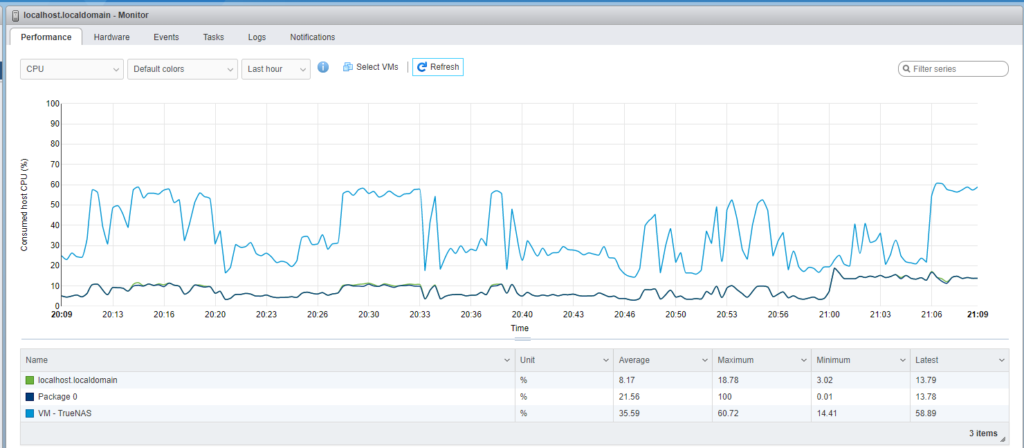
How hard is it take implement?
Provided you have the resources, then fairly easy with the key indicator being time. If you have additional drives somewhere and you are currently running TrueNAS you would just need to enable dedupe for the dataset and then begin to copy the files. Unfortunately, you can not have a currently running dataset and just hit enable. The only way I am aware of that TrueNAS can properly keep track and turn on dedupe is by writing the location of the files to the memory table.
You can be lazy, mount multiple drive letters and copy from a non dedupe enabled filesystem to another. That is what I did during my initial draft of this article. By using my own desktop as a traffic cop, I mounted two drive letters to the two different file systems, main system dataset: R430-6TB-Z2 and then the dedupe filesystem at R430-6TB-Z2\Vault. It was incredibly slow with hundreds of thousands of files.
Here is what Windows reported for the file copy of a single directory.
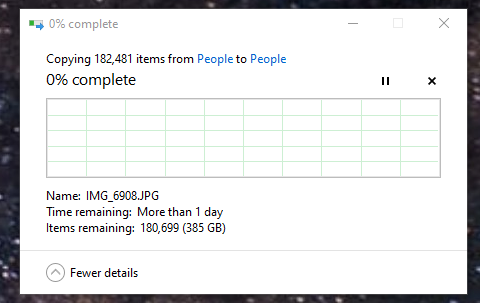
Compared to the totality that encompasses 1.4 million files that is a lot of small files that need to be written to multiple drives in a ZFS RAIDZ2 configuration.
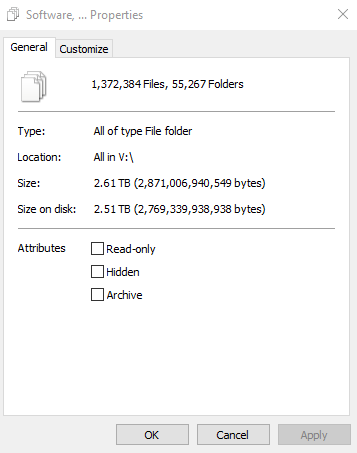
Frankly, the lazy approach was terrible. I figured I could just start a copy and do something else for the weekend, but that was not the case. My system locked up multiple times during the process forcing me to babysit it and in the end it was not a complete replica. When I queried the folders and files, I could see that there were some slight differences and missing files due to the missing files containing special characters.
Eventually, I just went directly into the TrueNAS shell, ran cp -R and copied over the all of the missing files I needed until the numbers matched correctly, and then ran rm -R -f on those directories I was decommissioning because Windows was unable to delete some of the files. It will always be faster going to the source of truth.
References: